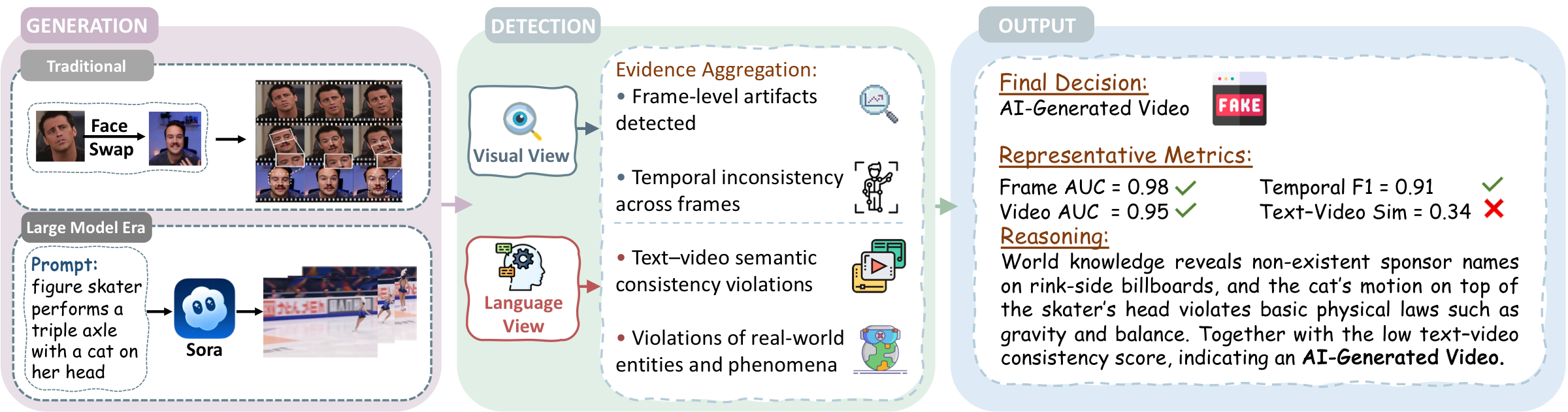
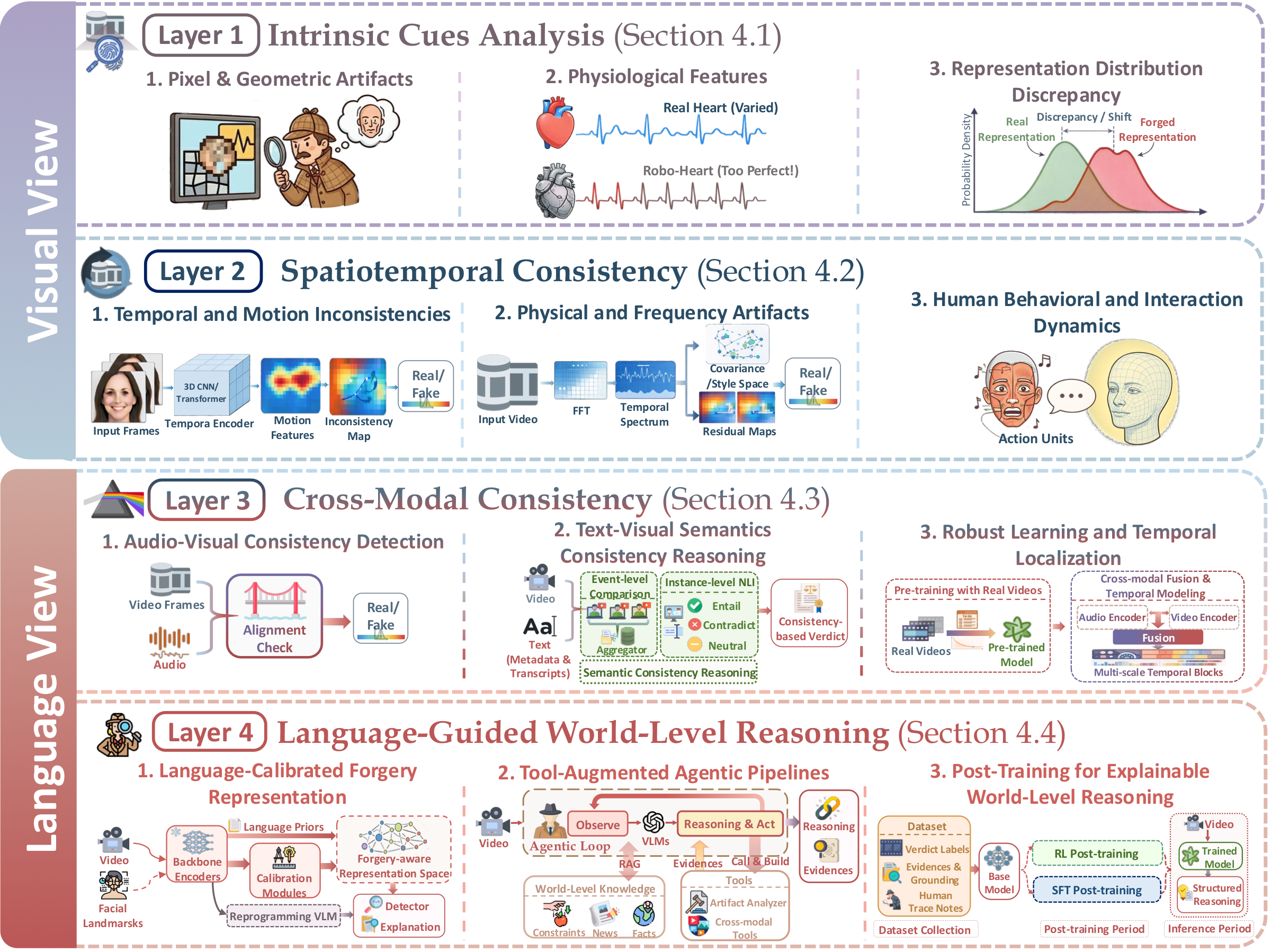
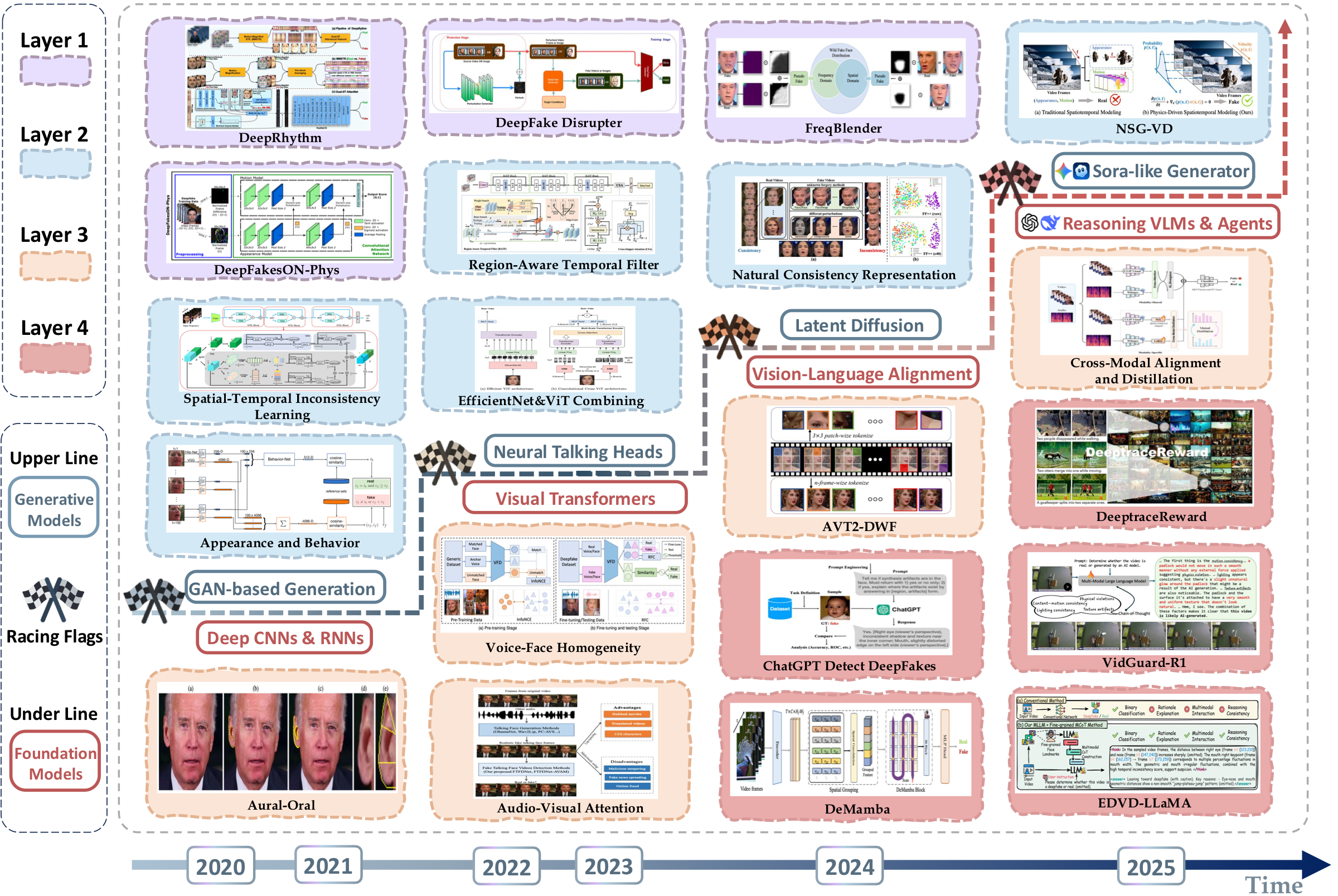
Challenges and Future
Toward evidence-first and trustworthy AIGC-V detection.
The next phase is not just stronger clip-level discrimination. It requires diagnostic evaluation, claim-level supervision, unified explainable detection, and deployment protocols that preserve calibration when evidence is weak, conflicting, or incomplete.
01
Robust diagnostic evaluation
Move beyond clip-level AUC or EER. Evaluation should reveal which factual proposition fails, where the violation occurs, and how brittle the detector becomes under shift, transfer, codec changes, and modern synthesis pipelines.
02
Claim-level and dynamic evaluation
Benchmarks should move from clip labels to checkable claims with timestamped evidence, targeted stress tests, and continuously refreshed generator pools rather than static one-off test sets.
03
Unified explainable detection
Trustworthy AIGC-V detection is a two-pathway problem: perceptual evidence plus fact-level verification. Cross-layer fusion should preserve low-level traces, localized mismatches, and tested claims as individually inspectable evidence objects.
04
Evidence-first trustworthy detection
Systems should identify, localize, and explain with calibrated uncertainty, provenance-aware cross-checks, and abstention when evidence remains incomplete or internally contradictory.
Broader research direction
Progress on trustworthy AIGC-V detection will likely require tighter collaboration between CV and NLP: CV contributes grounded perceptual and spatiotemporal evidence, while NLP contributes claim decomposition, retrieval, reasoning, grounding, and evidence-aware explanation in a unified evidence graph that also supports provenance checks, calibration, and abstention.